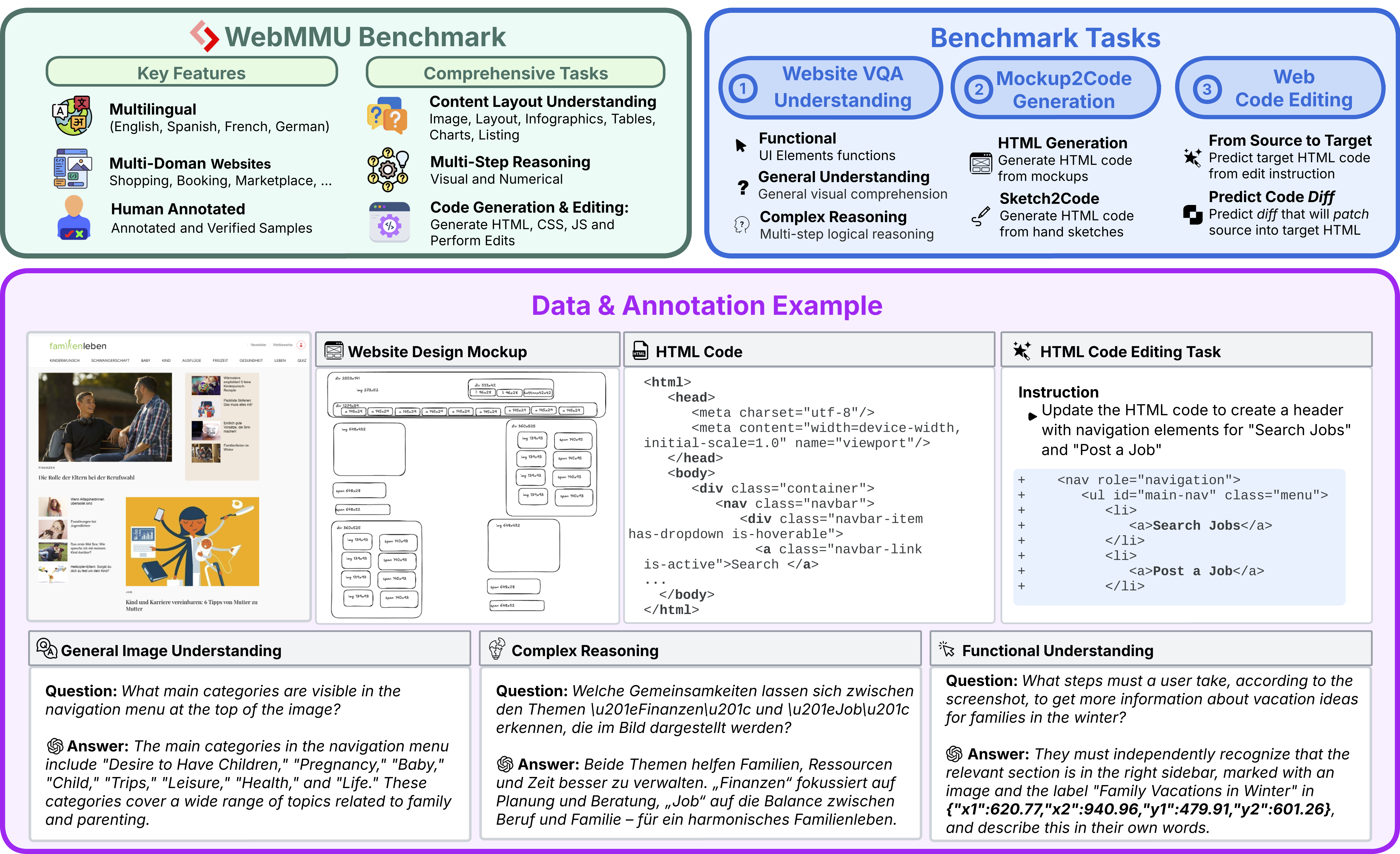
WebMMU's comprehensive evaluation reveals significant gaps in current AI capabilities for real-world web interaction. Our results provide actionable insights for researchers and developers working on multimodal AI systems.
Grounding Is the Hardest, Reasoning Comes Next, General Understanding Is the Easiest
WebMMU shows a clear difficulty gap across tasks. Most models handle basic visual understanding (like reading labels and identifying images) fairly well. They do worse at multi-step reasoning, such as performing calculations or combining information from different parts of a web page. But the hardest challenge is grounding — identifying the exact location of elements on a page and reasoning about user actions (e.g., where to click). For example, while many models could list navigation categories correctly, few could pinpoint where to click to open the "About Us" page, with grounding accuracy often falling below 10%. This reflects a gap between recognizing content and understanding how users interact with it.
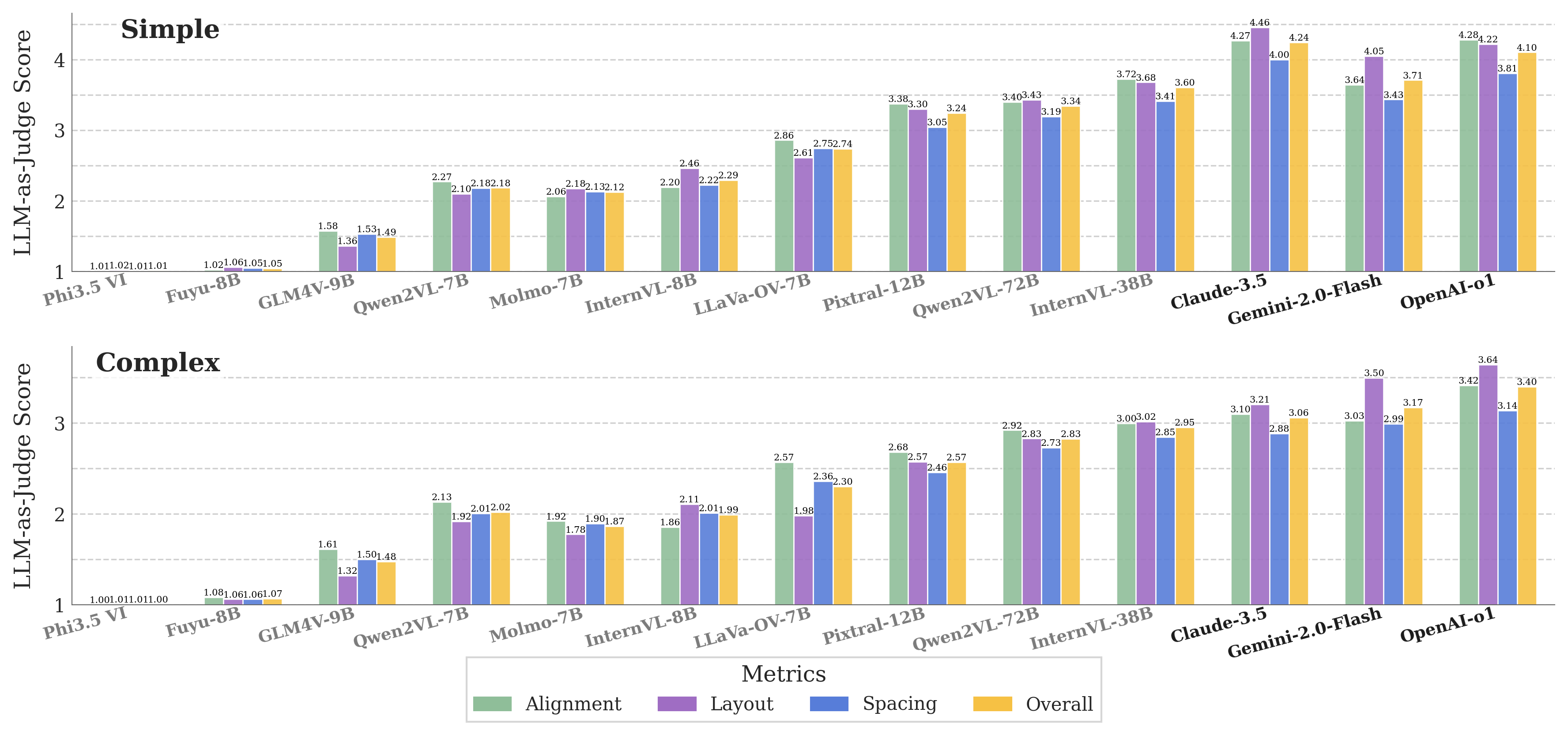
Simple Layouts Are Fine, But Complex UI Hierarchies Break the Models
When turning design mockups into HTML/CSS code, most models succeed on simple, flat layouts. But as soon as mockups include nested sections, multi-column layouts, or complex styling, the models break down. They often flatten the hierarchy, misalign elements, or miss relationships between components. For example, while they can correctly generate a basic "Contact Us" page, they struggle with a product page featuring sidebars, filters, and product grids. This suggests current models understand basic page layouts but lack deeper comprehension of modern, structured web design.
Code Editing: Models Generate Edits, But Risk Breaking the Site
In code editing tasks, models can follow instructions like "Add a header with search and post buttons," but often produce edits that break the site's structure or behavior. While the syntax of their HTML/CSS/JavaScript is mostly correct, they miss subtle dependencies, like class names or JavaScript functions, that keep the page functional. Even top models cannot yet generate reliable, ready-to-deploy code patches. This makes human review essential for all but the simplest edits.
Open-Source Models Lag Behind Closed-Source Models, Especially on Complex Tasks
Across all tasks, closed-source models like Gemini 2.0 Flash and Claude 3.5 consistently outperform open-source alternatives. They show better grounding, more accurate reasoning, and higher-quality code generation. For example, in the mockup-to-code task, closed-source models score above 4 out of 5 on simple layouts, while open-source models often struggle to score above 3. However, even the best models — closed or open — fail on complex designs, especially with nested layouts and precise spacing. Open-source models also suffer from greater multilingual performance drops, highlighting the training and resource gap between the two categories.
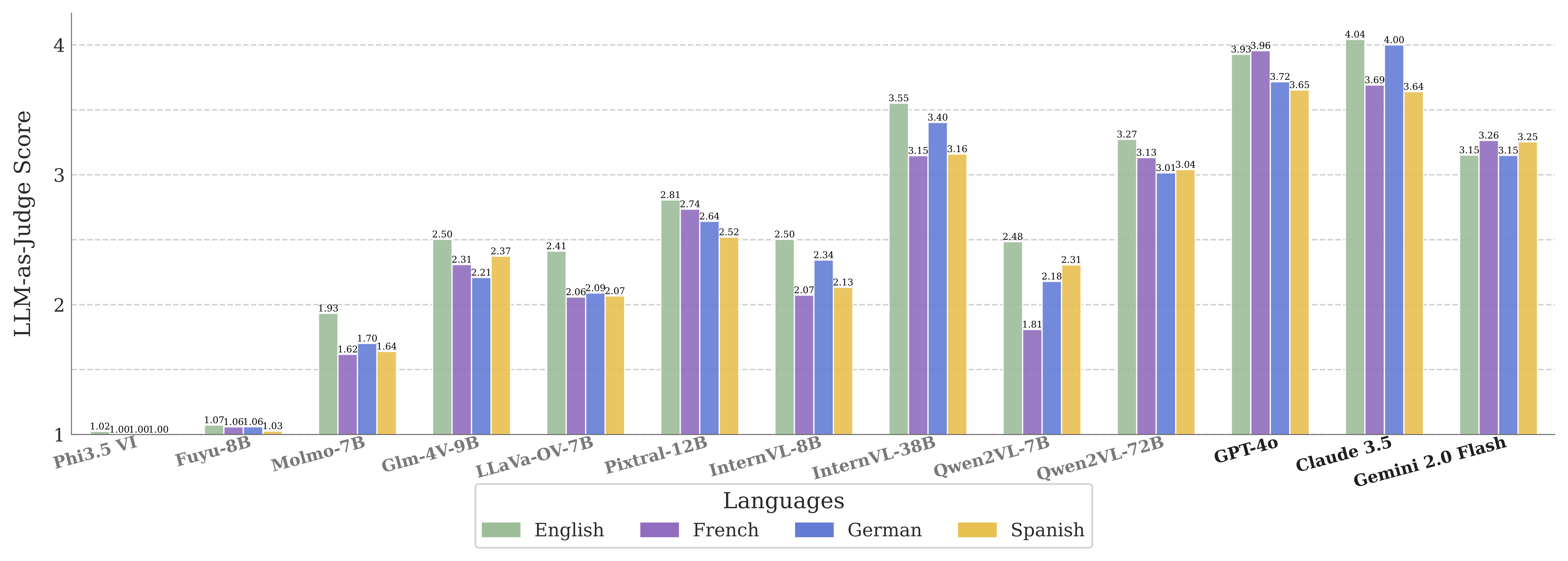
Multilingual Tasks Expose Major Gaps in Cross-Lingual Generalization
WebMMU covers English, Spanish, German, and French. Across all tasks, performance in non-English languages drops significantly — sometimes by more than half. Grounding and reasoning suffer most in these languages. This reveals that despite large training datasets, models haven't yet learned to generalize well to multilingual websites, which often have layout and content differences across languages.
The Big Picture: Real-World Web Automation Remains a Challenge
WebMMU shows that while AI models are progressing, they remain far from automating real-world web development. They can extract basic information and generate simple UI code, but they struggle with reasoning, structured code generation, precise edits, and multilingual scenarios. Closing this gap will require better multimodal reasoning, web-specific model architectures, and stronger cross-lingual capabilities — essential steps toward building truly intelligent web automation agents.